HyperWrite
Engineering Blog

Automating Stable Diffusion Prompting for (almost) Every Website
October 10, 2022
Author: Matt Shumer (matt@othersideai.com)
We took a few hours to add Stable Diffusion to our Hyperwrite Chrome extension to complement our text generation features. It was a pretty simple process, and we figured we’d share what we learned doing it.
The image space has been moving fast in recent years. CLIP was released a year and a half ago, followed by Stability AI's Stable Diffusion. This complements a growing ecosystem for generating text, from companies like OpenAI , Cohere, and others. The pace of generative AI releases seems to be accelerating, and it's a fun time to try to get these new technologies in front of the general public.
AI image generation has come a long way in the last few months. You can now get a high quality image generated in seconds, simply by writing a prompt (a short description of the desired image) for an AI. Since we’ve been building the Hyperwrite Chrome extension to generate text on every website, we thought it would be useful to also add the ability for our users to generate images using the same underlying tooling. We were happy to find that the ecosystem for deploying image generation has been developing rapidly, and we figured we’d share some lessons we learned.
For developers, there’s now a pretty diverse ecosystem of options for quickly deploying image models into production. For users, getting the most out of generative image models still requires lots of patience and understanding of the idiosyncrasies of each model. Whether using Stable Diffusion or Dall-e, you'll notice that many of the most beautiful and detailed images come from a very small number of people who have mastered the art of prompt engineering. Their prompts look quite different from the simple, human-understandable requests we might put in.
For example, a prompt with the goal of generating an image of a fire might look like this: "image of fire, long exposure, 8k, dslr, photorealistic, full color, via photopin and shutterstock"
This is the kind of prompt that only a true master of the art could come up with. How did they know to include all of those details? How did they know what effect each one would have on the final image? And more important, how do you make it so everyone else can figure that out?
We aren’t true masters of image prompting, and we don’t expect most people to become one, so we decided to abstract away the image prompting process from the user by running the user input through a regular text model first to generate the final image prompt. This way, our users can generate high-quality images with just a few clicks, without needing to worry about the details of the image prompting process. With this in mind, here is how we got there and made it easy for our users to access one-click Stable Diffusion on almost any website on the internet.
Deploying a Model (Pros and Cons)
We thought about deploying our own models at first. Over the last few months, there’s been a growing number of options for doing this, from grabbing a notebook someone posted on Twitter a few minutes ago to using a Huggingface pipeline to run a model on your own. Right now, you still need GPUs to run most image generation models, but getting them isn’t too difficult. We use Zeet to manage our Coreweave GPUs which we’ve found to be a pretty reliable method for most of our projects. However, running an A100 GPU is around $2.20 per hour, and running Stable Diffusion takes around 10 seconds for four images. If you’re worried about concurrency, the costs can go up a bit, so we figured we’d wait until there was enough usage to justify keeping up our own models.
If you don’t care about hosting the model yourself, sites like Replicate provide API access to models. You simply drop in their API key and you can start calling them immediately with POST requests. The downside is you don’t have as much control over the model as you would if you ran it yourself, so you can’t implement the newest improvements as they come out. But the upside is that Replicate will likely implement new changes before we can get around to it. We suspect that this is actually the biggest reason to use a service like this; unless you’re able to have someone focusing on upgrading the models, outsourcing the task of updating the models to a service like Replicate makes sense.
Integrating into Websites
To generate an image, the main thing we need to do is grab some text from the page or from the user. We already have the ability to send up a text command to our APIs with our AutoWrite feature, which takes a text input and sends it up to our API with some additional information from the page. We simply added an extra parameter for mode, so that images get re-routed to a different generation function on the API. This way, we can pass the Stable Diffusion prompt to a Stable Diffusion model, rather than to a GPT model. and pass the Stable Diffusion prompt to a Stable Diffusion model rather than to a GPT model.
We did have to worry a little bit about how to handle images after they’ve been generated. We just convert them into base 64 and send them to the frontend to cast them back into images. We debated just hosting the images and sending the URLs, but we decided against it since we don’t want to mess with hosting at the moment. However, we may eventually have to do something with that.
We have a Rewrite feature that takes highlighted text from a page and does a text transformation on it. We hooked image generation into that too, but ran into an obvious problem: text written for human consumption isn’t going to play nicely with the formatting Stable Diffusion expects. So we need to process it a bit before feeding it into the image model. For instance, if you have a Google Slide, you just want to be able to say “write me a cover art for this presentation”, without typing out the minute details of the presentation. Since we’ve got the text of the page, we just threw up a quick GPT few-shot prompt that summarizes text into what the image accompanying the text would look like, and then we feed that into the image model.
That being said, for Google Slides in particular we haven’t yet figured out how to scrape it nicely (or add text nicely). Regardless, we can read the page in at least a sketchy sense most of the time - but we can’t necessarily detect how much of a section the user’s selected. We can figure that out later and it works well enough for now.
So now we have the option of auto-formatting a page of text to standard diffusion-readable text, or letting the user write it out themselves! Except we forgot a key piece of software engineering: educating users on writing out complex prompts is hard. However, since we had already made it so we can reformat arbitrary page text to Stable Diffusion-formatted text, we just applied the same formatting to the user input. This way, we can avoid having to educate the users on the diffusion formatting process! At some point, we probably will need to figure out UI/UX for adding toggles, but we haven’t figured that out yet.
At this point it’s probably worth talking about the tradeoffs of abstracting the Stable Diffusion controls away from the user.
Automating Prompt Engineering
Our main thesis boils down to rejecting the notion that every user (including most of our engineers) of current machine learning models should have to become a prompt engineering expert in order to get great results. If the average user wants to generate an image of a fire, they shouldn’t need to worry about all of the details. They just ask for an image of a fire, and our AI will take care of the rest.
This itself is an engineering problem, although the path for solving it is somewhat simple, it seems. Models like Stable Diffusion and GPT-3 are powerful on their own, but they’re even more powerful when used together. We can take advantage of language models to generate a large amount of data, which we then use to train a fine-tuned language model that essentially does prompt engineering for us. We use this for translating between text prompts and images, but it’s likely applicable to a bunch of different tasks.
To do this, we first generated a large number of possible image searches with GPT-3. For example, “an image of a fire” or “a picture of a cat on a beach.”
Next, we used the Lexica API to search for each of those terms and collect a variety of different prompts that users generated. For each term, we collected the best prompts (a naive way to do this would be to just choose the longest prompts, but there are other ways to evaluate quality that we won’t go into here).
Then, we used another GPT-3 system to simplify those prompts to what a human would ask for. For example, the prompt “image of fire, long exposure, 8k, dslr, photorealistic, full color, via photopin and shutterstock” would be simplified to “an image of a fire.”
This enabled us to quickly build a large dataset of human-readable requests and their corresponding prompt engineered prompts.
Finally, we fine-tuned GPT-3 on this dataset so that it could take a human prompt and convert it to an engineered prompt.
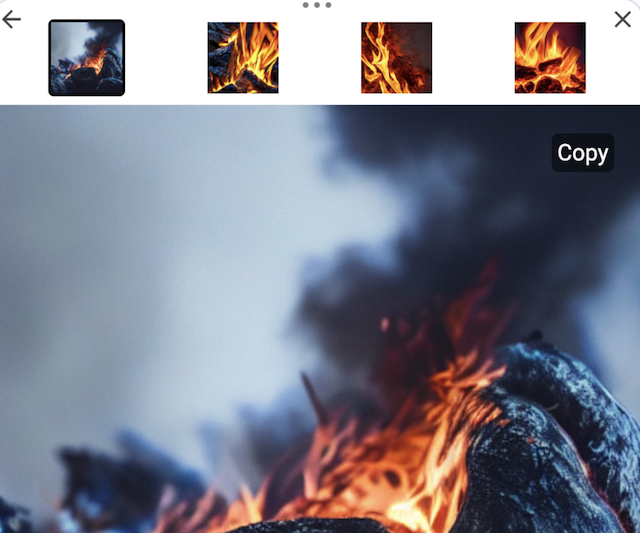
The result is a system that can take a simple request like “an image of a fire” and generate a high-quality image, with all of the details that are typically only achievable with custom prompt engineering.
The images generated by our system are not perfect, but they are of a much higher quality than what is typically achievable without prompt engineering. And, importantly, they are generated automatically, without the need for any specialized knowledge or expertise. At some point we’d start benchmarking performance on different tasks, but we can also just A/B test in the background with accept rates on different models and figure it out that way.
We’re just getting started with this approach and there is a lot of work still to be done. But we believe that this is a powerful way to automatically generate high-quality images, and we’re excited to see what else we can do with it.
If you’re interested in these types of difficult problems and want to work with us to push the limits of what is possible when it comes to helping people use AI across the web, reach out! We’re hiring frontend engineers (though we’re still open to chatting with backend engineers and anyone else who might be interested).